
Background
Read up on GraphQL concepts and authenticating with our API. To form requests, refer to our primer on our GraphQL API.
For clarity, each request will be shown as just the body of the POST request. If you are using cURL, please refer to the primer on our GraphQL API for how to structure requests.
The Finale User Interface (UI) uses the same GraphQL queries shown in this guide. For more detailed examples with your own company’s data, we suggest utilizing the network tab in Chrome’s developer tools to inspect actual GraphQL POST requests.
Overview
Imports in our GraphQL API utilizes our Jobs API. To import a set of data, we need to:
- Query list of existing and running jobs (optional)
- Create a job with data to import
- Query and inspect the newly created job
- Query metadata for columns available for import
- Mutate the job to assign proper columns to the raw import data
- Mutate the job to start it
- Mutate the job to cancel it (optional)
Query list of existing and running jobs (optional)
To see a list of currently running jobs, use the following query:
{
"query":"query ($user: String) { job(user: $user, status: [\"JOB_COMMITTED\"]) { edges { node { jobUrl status parameters { type term } } } } } ",
"variables":{"user":"/demo/api/userlogin/test"},
}If there are no running jobs, this will return:
{"data":{"job":{"edges":\[] } } }If there are running jobs, this will return:
{"data":{"job":{"edges":[
{"node":{"jobUrl":"/demo/api/job/10000","status":"Started","parameters":{"type":"##rows","term":"sale"}}}
] } } }This query uses a filter on the user and status of the job. The user login is the same userLoginUrl returned in the authentication response. The status filter uses our internal representation of the job status, with the following available values:
- Draft:
JOB_INPUT - Started:
JOB_COMMITTED - Completed:
JOB_COMPLETED - Canceled:
JOB_CANCELLED
We recommend always using a user filter and only querying on jobs with the status Draft or Started. This is because of the large number of jobs that are on some accounts.
Create a job with data to import
Assuming that your import looks like this:
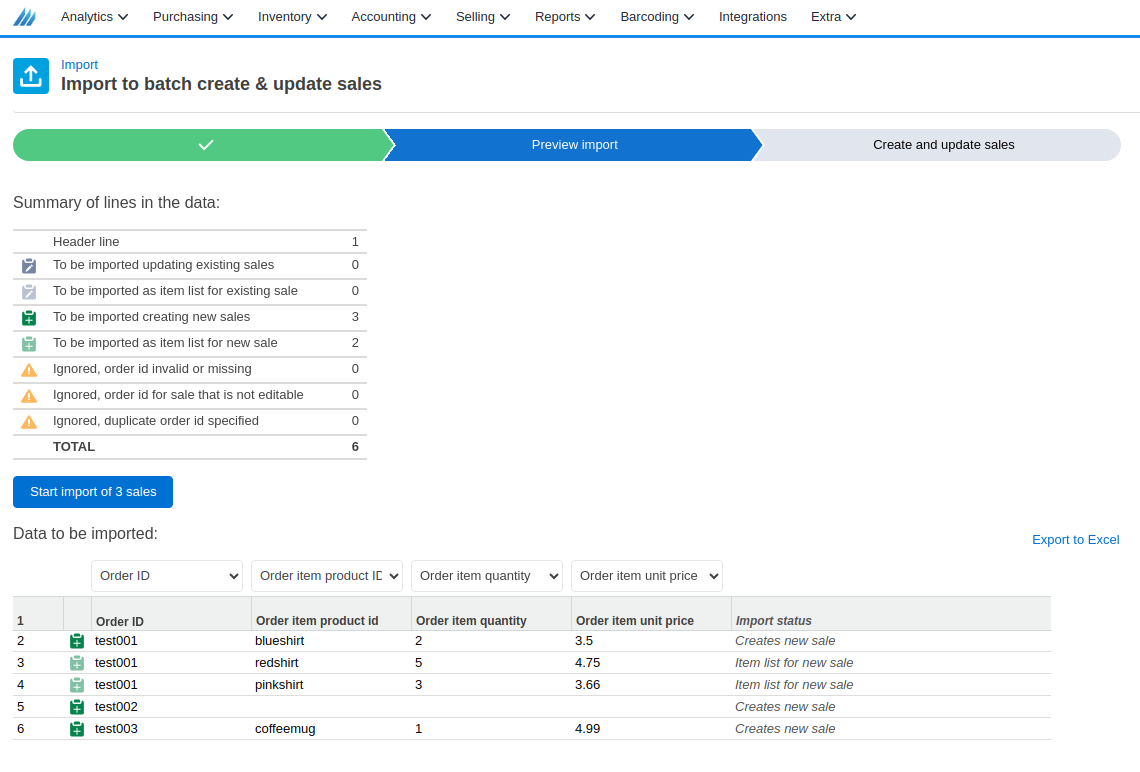
Your import job would look like this:
{
"query": "mutation ($content: String, $term: String!, $userDate: String!) { jobCreate(input: {content: {body: $content}, parameters: {type: \"##rows\", term: $term, columnIndexes: [], userDate: $userDate}}) { job { jobUrl } } }",
"variables": {
"content": "[[\"Order ID\", \"Order item product id\",\"Order item quantity\",\"Order item unit price\"],[\"test001\",\"blueshirt\",\"2\",\"3.50\"], [\"test001\",\"redshirt\",\"5\",\"4.75\"],[\"test001\",\"pinkshirt\",\"3\",\"3.66\"], [\"test002\",\"\",\"\",\"\"],[\"test003\",\"coffeemug\",\"1\",\"4.99\"]]",
"userDate": "2025-05-28T19:00:00.000Z",
"term": "sale"
},
}The content of the data is a JSON representation of an array of rows being imported. Formatted, the content variable looks like this:
[
["Order ID", "Order item product id","Order item quantity","Order item unit price"],
["test001","blueshirt","2","3.50"],
["test001","redshirt","5","4.75"],
["test001","pinkshirt","3","3.66"],
["test002","","",""],
["test003","coffeemug","1","4.99"]
]Notice that in the variables, numeric values are sent in as strings. For importing, we expect every value to be either a string or null.
This will return:
{"data":{"jobCreate":{"job":{"jobUrl":"/demo/api/job/10000"}}}}Query and inspect the newly created job
Use the jobUrl in future requests to inspect and mutate our import. There are a couple ways to inspect the import job we just created. To get a summary, we can use the following query:
{
"query": "query ($jobUrl: String) { job(jobUrl: $jobUrl) {
edges {
node {
status parameters { term columnIndexes { field index } }
itemSummary { itemTypeCount { label count value } }
itemList(first: 1) {
edges { node { row { value warning } } }
pageInfo { hasNextPage endCursor } } } } } }",
"variables": {jobUrl: "/demo/api/job/10000"}
}This will return:
{
"data": {
"job": {
"edges": \[ { "node": {
"status": "Draft",
"parameters": { "term": "sale", "columnIndexes": \[] },
"itemSummary": {
"itemTypeCount": [
{
"label": "Header line",
"count": 1,
"value": "header"
},
...
{
"label": "Ignored, order id invalid or missing",
"count": 5,
"value": "noEntityIdentifier"
},
...
]
},
"itemList": {
"edges": \[
{ "node": { "row": [{ "value": "Order ID", "warning": null }] } }
],
"pageInfo": { "hasNextPage": true, "endCursor": "eyJpZHgiOjB9" }
} } } ] } } }Using this, we can inspect a paginated view of the import job with item details:
{
"query": "query ($jobUrl: String, $after: String, $first: Int) { job(jobUrl: $jobUrl) {
edges {
node {
itemList(after: $after, first: $first) {
edges { node { rowStatus rowStatusRaw: rowStatus(formatter: "raw") row { value warning } } }
pageInfo { hasNextPage endCursor } } } } } }",
"variables": {jobUrl:"/demo/api/job/10000", after:"eyJpZHgiOjB9", first: 100},
}This will return:
{
"data": {
"job": {
"edges": \[
{
"node": {
"itemList": {
"edges": \[
{
"node": {
"rowStatus": "Ignored, order id invalid or missing",
"rowStatusRaw": "noEntityIdentifier",
"row": [
{ "value": "testorder001", "warning": null },
{ "value": "redshirt", "warning": null },
{ "value": "2", "warning": null },
{ "value": "3.50", "warning": null },
]
}
},
{ ... }, ...
],
"pageInfo": {
"hasNextPage": false,
"endCursor": "eyJpZHgiOjJ9"
} } } } ] } } }Couple notes: processing imports may take some time depending on the size of the import and the size of the account. Large accounts creating imports for 100,000+ rows may have to poll this endpoint until the total count of rows in the summary of the results is greater than 1. This process should not take more than a few minutes maximum, but for most users this process should take less than 5 seconds.
When querying for the full list of job import rows, we paginate the response. Take a look at the official GraphQL docs on pagination for guidance.
Also, you may notice that we already have rows with errors on the import, indicated by the summary and the row status on the paginated GraphQL import job. This is due to the import not recognizing the header rows we sent for their internal column fields. Our UI handles this automatically with GraphQL requests.
Query metadata for columns available for import
To populate the column headers with their correct internal column fields for import, we must get the definitions of columns with user friendly labels and their corresponding internal column fields:
{
"query": "query ($purpose: String) { importScreenDefinition(purpose: $purpose) { entityIdDimensionKey columnDefinitions { label field groupLabel } } }",
"variables": {purpose: "uiSalesOrder"},
}This will return:
{
"data": {
"importScreenDefinition": {
"entityIdDimensionKey": "orderOrderId",
"columnDefinitions": [
{
"label": "Customer",
"field": "orderCustomer",
"groupLabel": null
},
...
{
"label": "Order item product ID",
"field": "orderItemProductId",
"groupLabel": "Order Item"
},
{
"label": "Order item quantity",
"field": "orderItemQuantity",
"groupLabel": "Order Item"
},
{
"label": "Order item unit price",
"field": "orderItemUnitPrice",
"groupLabel": "Order Item"
},
{
"label": "Order date",
"field": "orderOrderDate",
"groupLabel": null
},
{
"label": "Order ID",
"field": "orderOrderId",
"groupLabel": null
},
//...
] } } }There are many more columns available for import depending on the account (includes user defined fields and adjustment presets).
The purpose variable in this request is an internal identifier that may not be immediately visible using introspection on the GraphQL API. Instead, inspect the GraphQL requests being run when using the UI import screens to find the correct purpose string for your specific import. Some examples are:
uiBuild: build with item importuiSalesOrder: sales with item importuiPurchaseOrder: purchases with item importuiSublocation: sublocation import
Mutate the job to assign proper columns to the raw import data
In order to update our job import to assign the correct internal names to the correct columns, we must use the field value from the importScreenDefinition query above:
{
"query": "mutation ($jobUrl: String!, $term: String!) { jobUpdate(input: {jobUrl: $jobUrl, parameters: { \\type: "##rows", term: $term, columnIndexes: [
\field{ :orderOrderId" index", 0:
},field\ {orderItemProductID: index" 1",
:field}, \orderItemQuantity{ index: 2"
",field: },orderItemUnitPrice\ index{3:
"]}}) { job { parameters { columnIndexes { field index } } } } }",
"variables": {jobUrl: "/demo/api/job/10000", term: "sale"},
}This will return:
{
"data": {
"jobUpdate": {
"job": {
"parameters": {
"columnIndexes": [
{field: "orderOrderId", index: 0},
{field: "orderItemProductID", index: 1},
{field: "orderItemQuantity", index: 2},
{field: "orderItemUnitPrice", index:3}
] } } } } }This confirms that our update was successful. If we query against the job again, we will see that the status for each job item is correct and data has been parsed to match our internal representation:
Mutate the job to start it
Get response of update with test data.
If everything looks correct, we can start the import job by modifying the import job itself:
{
"query": "mutation ($jobUrl: String!, $status: String) { jobUpdate(input: {jobUrl: $jobUrl, status: $status}) { job { status } } }",
"variables": {jobUrl: "/demo/api/job/10000", status: "Started"}
}This causes the server to queue up the import job in our internal scheduling system, and will be processed in chunks of 100. To check the status of your running job:
{
"query": "query ($jobUrl: String) { job(jobUrl: $jobUrl) { edges { node { status itemSummary { statusIdCount { label count } } } } } }",
"variables": {jobUrl: "/demo/api/job/10000"},
}Mutate the job to cancel it (optional)
If you need to suddenly stop your import, you can do so:
{
"query": "mutation ($jobUrl: String!, $status: String) { jobUpdate(input: {jobUrl: $jobUrl, status: $status}) { job { status } } }",
"variables": {jobUrl: "/demo/api/job/10000", status: "Canceled"},
}Since we process imports in chunks of 100, your import will stop processing before the next chunk of 100 entities to import.